| SQL进阶技巧 | 您所在的位置:网站首页 › sql 高级进阶 › SQL进阶技巧 |
SQL进阶技巧
|
关于SQL我之前已经陆续更新了很多期,从入门到基础知识再到练习和面试技巧都有分享,大家感兴趣的话可以去看下这篇文章。 戎易大数据:几万字汇总了SQL全部知识点,必看!(含教程、面试技巧) 近几期主要围绕SQL进阶技巧来进行分享。  本篇主题为自连接的用法。 SQL可以在不同的表或者视图间进行连接运算,同时也可以对相同的表进行“自连接”运算。不过由于自连接的过程不太容易理解,所以大家经常避免使用自连接,但自连接用熟练了,也不失为一种方便的技术。 今天这篇文章将为大家介绍SQL的自连接用法。 理解了自连接不仅可以提高我们的SQL能力,还能增进我们对“面向集合”这一SQL语言重要特征的理解。面向对象语言以对象的方式来描述世界,而面向集合语言SQL以集合的方式来描述世界,其中自连接技术充分体现了SQL面向集合的特性。 接下来我们将分几种应用情景来介绍SQL自连接的用法。 01、可重排列、排列、组合假设有一张存放了商品名称及价格的表,表中有“苹果、橘子、香蕉”这3条数据。在生成用于查询销售额的报表的时候,我们可能会需要获取这些商品的组合。  这里所说的组合其实分为两种类型。一种是有顺序的有序对,另一种是无顺序的无序对。有序对用尖括号括起来,如;无序对用花括号括起来,如{1, 2}。在有序对里,如果元素顺序相反,那就是不同的对,因此≠;而无序对与顺序无关,因此{1, 2}={2, 1}。用术语来说,这两类分别对应着“排列”和“组合”。 用SQL生成有序对非常简单。像下面这样通过交叉连接生成笛卡儿积(直积),就可以得到有序对。 --用于获取可重排列的SQL语句 SELECT P1.name AS name_1, P2.name AS name_2 FROM Products P1, Products P2;结果: name_1 name_2 ------ ------ 苹果 苹果 苹果 橘子 苹果 香蕉 橘子 苹果 橘子 橘子 橘子 香蕉 香蕉 苹果 香蕉 橘子 香蕉 香蕉执行结果里每一行都是一个有序对。因为是可重排列,所以结果行数为32=9。结果里出现了(苹果,苹果)这种由相同元素构成的对,而且(橘子,苹果)和(苹果,橘子)这种只是调换了元素顺序的对也被当作不同的对了。这是因为,该查询在生成结果集合时会区分顺序。 接下来,我们思考一下如何更改才能排除掉由相同元素构成的对。首先,为了去掉(苹果,苹果)这种由相同元素构成的对,需要像下面这样加上一个条件,然后再进行连接运算。 --用于获取排列的SQL语句 SELECT P1.name AS name_1, P2.name AS name_2 FROM Products P1, Products P2 WHERE P1.name P2.name;结果: name_1 name_2 ------ ------ 苹果 橘子 苹果 香蕉 橘子 苹果 橘子 香蕉 香蕉 苹果 香蕉 橘子加上WHERE P1.name P2.name这个条件以后,就能排除掉由相同元素构成的对,结果行数为排列。理解这个连接的关键在于想象一下这里存在下面这样的两张表。 不能有(苹果,苹果)这样的组合  当然,无论是P1还是P2,实际上数据都来自同一张物理表Product。但是,在SQL里,只要被赋予了不同的名称,即便是相同的表也应该当作不同的表(集合)来对待。也就是说,P1和P2可以看成是碰巧存储了相同数据的两个集合。这样的话,这个自连接的处理结果就成了下面这样。 ● P1里的“苹果”行的连接对象为P2里的“橘子、香蕉”这两行 ● P1里的“橘子”行的连接对象为P2里的“苹果、香蕉”这两行 ● P1里的“香蕉”行的连接对象为P2里的“苹果、橘子”这两行 由此我们可以认为,相同的表的自连接和不同表间的普通连接并没有什么区别,自连接里的“自”这个词也没有太大的意义。这次的处理结果依然是有序对。 接下来我们进一步对(苹果,橘子)和(橘子,苹果)这些只是调换了元素顺序的对进行去重。请看下面的SQL语句。 --用于获取组合的SQL语句 SELECT P1.name AS name_1, P2.name AS name_2 FROM Products P1, Products P2 WHERE P1.name > P2.name;结果: name_1 name_2 ------ ------ 苹果 橘子 香蕉 橘子 香蕉 苹果同样地,请想象这里存在P1和P2两张表。在加上“不等于”这个条件后,这条SQL语句所做的是,按字符顺序排列各商品,只与“字符顺序比自己靠前”的商品进行配对,结果行数为3。到这里,我们终于得到了无序对。恐怕平时我们说到组合的时候,首先想到的就是这种类型的组合吧。 想要获取3个以上元素的组合时,像下面这样简单地扩展一下就可以了。这次的样本数据只有3行,所以结果应该只有1行。 --用于获取组合的SQL语句:扩展成3列 SELECT P1.name AS name_1, P2.name AS name_2, P3.name AS name_3 FROM Products P1, Products P2, Products P3 WHERE P1.name > P2.name AND P2.name > P3.name;结果: name_1 name_2 name_3 ------- -------- -------- 香蕉 苹果 橘子如这个例子所示,使用等号“=”以外的比较运算符,如“、”进行的连接称为“非等值连接”。这里将非等值连接与自连接结合使用了,因此称为“非等值自连接”。在需要获取列的组合时,我们经常需要用到这个技术。 最后补充一点,“>”和“ 接下来,我们来学习一下使用关联子查询删除重复行的方法。连接和关联子查询虽然是不同的运算,但是思路很像,而且很多时候它们的SQL在功能上是等价的,所以在这里我们一并了解一下。 不需要关注重复行具体有多少重复。通常,如果重复的列里不包含主键,就可以用主键来处理,但像这个例子一样所有的列都重复的情况,则需要使用由数据库独自实现的行ID。这里的行ID可以理解成拥有“任何表都可以使用的主键”这种特征的虚拟列。在下面的SQL语句里,我们使用的是Oracle数据库里的rowid。 --用于删除重复行的SQL语句(1):使用极值函数 DELETE FROM Products P1 WHERE rowid < ( SELECT MAX(P2.rowid) FROM Products P2 WHERE P1.name = P2. name AND P1.price = P2.price ) ;这个关联子查询的处理乍看起来不是很好理解。其实,关联子查询正如其名,就是用来查找两张表之间的关联性的,而这里只有一张表,却也跟“关联”扯上了关系,想必大家都心存疑问吧。 之所以大家会有这种疑问,是因为没有从正确的层面来理解这条SQL语句。请像前面的例题里讲过的一样,将关联子查询理解成对两个拥有相同数据的集合进行的关联操作。 P1:  P2: 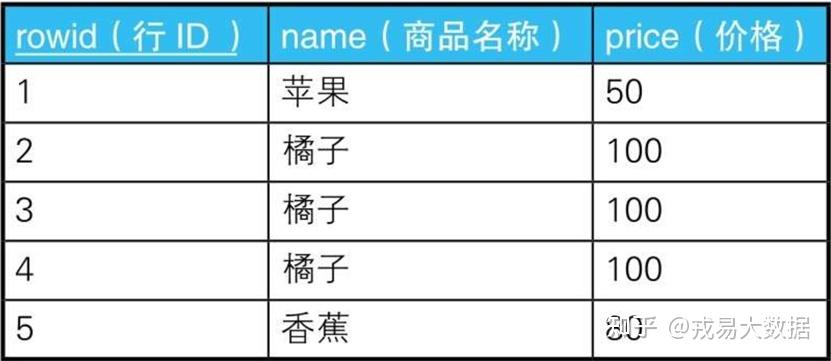 这里的重点也与前面的例子一样,对于在SQL语句里被赋予不同名称的集合,我们应该将其看作完全不同的集合。这个子查询会比较两个集合P1和P2,然后返回商品名称和价格都相同的行里最大的rowid所在的行。 于是,由于苹果和香蕉没有重复行,所以返回的行是“1:苹果”“5:香蕉”,而判断条件是不等号,所以该行不会被删除。而对于“橘子”这个商品,程序返回的行是“4:橘子”,那么rowid比4小的两行——“2:橘子”和“3:橘子”都会被删除。 通过这道例题我们明白,如果从物理表的层面来理解SQL语句,抽象度是非常低的。“表”“视图”这样的名称只反映了不同的存储方法,而存储方法并不会影响到SQL语句的执行和结果,因此无需有什么顾虑(在不考虑性能的前提下)。无论表还是视图,本质上都是集合——集合是SQL能处理的唯一的数据结构。 此外,用前面介绍过的非等值连接的方法也可以写出与这里的执行过程一样的SQL语句。 --用于删除重复行的SQL语句(2):使用非等值连接 DELETE FROM Products P1 WHERE EXISTS ( SELECT * FROM Products P2 WHERE P1.name = P2.name AND P1.price = P2.price AND P1.rowid < P2.rowid );03、查找局部不一致的列假设有下面这样一张住址表,主键是人名,同一家人家庭ID一样。在寄送新年贺卡等时,也许有人会制作这样一张表吧。  一般来说,同一家人应该住在同一个地方(如加藤家),但也有像福尔摩斯和华生这样不是一家人却住在一起的情况。接下来,我们看一下前田夫妇。这两个人并没有分居,只是夫人的住址写错了而已。前面说了,如果家庭ID一样,住址也必须一样,因此这里需要修改一下。那么我们该如何找出像前田夫妇这样的“是同一家人但住址却不同的记录”呢? 实现办法有几种,不过如果用非等值自连接来实现,代码会非常简洁。 --用于查找是同一家人但住址却不同的记录的SQL语句 SELECT DISTINCT A1.name, A1.address FROM Addresses A1, Addresses A2 WHERE A1.family_id = A2.family_id AND A1.address A2.address ;这条SQL语句逐词翻译了“是同一家人,但住址却不同”这个条件,相信大家都能看明白。可以看到,像这样把自连接和非等值连接结合起来确实非常好用。这条SQL语句不仅可以用于发现不规则的数据,而且修改一下也可以用来查找商品,比如下面这个例子。 问题:从下面这张商品表里找出价格相等的商品的组合。 Products  方法: 家庭ID→价格 住址→商品名称 像上面这样替换一下。然后,代码就会变成下面这样。 --用于查找价格相等但商品名称不同的记录的SQL语句 SELECT DISTINCT P1.name, P1.price FROM Products P1, Products P2 WHERE P1.price = P2.price AND P1.name P2.name;结果: name price ------ ------ 苹果 50 葡萄 50 草莓 100 橘子 100 香蕉 100请注意,这里与住址表那道例题不同,如果不加上DISTINCT,结果里就会出现重复行。关键在于价格相同的记录的条数。而就住址表的例题来说,如果前田家有孩子,那么不在代码中加上DISTINCT的话,结果里才会出现重复行。不过,这道例题使用的是连接查询,如果改用关联子查询,就不需要DISTINCT了。大家可以把这当作练习题,试着改写一下。 04、排序在使用数据库制作各种票据和统计表的工作中,我们经常会遇到按分数、人数或销售额等数值进行排序的需求。某些数据库管理系统(DBMS)已经实现了这样的功能(如Oracle、DB2数据库的RANK函数等)。 现在,我们要按照价格从高到低的顺序,对下面这张表里的商品进行排序。我们让价格相同的商品位次也一样,而紧接着它们的商品则有两种排序方法,一种是跳过之后的位次,另一种是不跳过之后的位次。  如果使用窗口函数,可以像下面这样实现。 --排序:使用窗口函数 SELECT name, price, RANK() OVER (ORDER BY price DESC) AS rank_1, DENSE_RANK() OVER (ORDER BY price DESC) AS rank_2 FROM Products;结果: name price rank_1 rank_2 ------- ------ ------- ------- 橘子 100 1 1 西瓜 80 2 2 苹果 50 3 3 香蕉 50 3 3 葡萄 50 3 3 柠檬 30 6 4在出现相同位次后,rank_1跳过了之后的位次,rank_2没有跳过,而是连续排序。代码很简洁,而且很容易理解。不过用到的RANK函数还属于标准SQL中较新的功能,需要较高版本的数据库才能实现。 接下来我们再考虑一下有没有不依赖于具体数据库来实现的方法。下面是用非等值自连接(真的很常用)写的代码。 --排序从1开始。如果已出现相同位次,则跳过之后的位次 SELECT P1.name, P1.price, (SELECT COUNT(P2.price) FROM Products P2 WHERE P2.price > P1.price) + 1 AS rank_1 FROM Products P1 ORDER BY rank_1;结果: name price rank ----- ------ ------ 橘子 100 1 西瓜 80 2 苹果 50 3 葡萄 50 3 香蕉 50 3 柠檬 30 6这段代码的排序方法看起来很普通,但很容易扩展。例如去掉标量子查询后边的+1,就可以从0开始给商品排序,而且如果修改成COUNT(DISTINCT P2.price),那么存在相同位次的记录时,就可以不跳过之后的位次,而是连续输出(相当于DENSE_RANK函数)。由此可知,这条SQL语句可以根据不同的需求灵活地进行扩展,实现不同的排序方式。 接下来,我们来了解一下这条SQL语句的执行原理。这道例题很好地体现了面向集合的思维方式。子查询所做的,是计算出价格比自己高的记录的条数并将其作为自己的位次。为了便于理解,我们先考虑从0开始,对去重之后的4个价格“{ 100,80, 50, 30 }”进行排序的情况。 首先是价格最高的100,因为不存在比它高的价格,所以COUNT函数返回0。接下来是价格第二高的80,比它高的价格有一个100,所以COUNT函数返回1。同样地,价格为50的时候返回2,为30的时候返回3。这样,就生成了一个与每个价格对应的集合,如下表所示。  也就是说,这条SQL语句会生成这样几个“同心圆状的”递归集合,然后数这些集合的元素个数。正如“同心圆状”这个词的字面意思那样,这几个集合之间存在如下包含关系。 S3 ∪ S2 ∪ S1 ∪ S0 集合里有集合,再往里还有集合……  实际上,“通过递归集合来定义数”这个想法并不算新颖。有趣的是,它和集合论里沿用了100多年的自然数(包含0)的递归定义在思想上不谋而合。研究这种思想的学者形成了几个流派,其中和这个例子的思路类型相同的是计算机之父、数学家冯·诺依曼提出的想法。冯·诺依曼首先将空集定义为0,然后按照下面的规则定义了全体自然数。 0 = φ 1 = {0} 2 = {0, 1} 3 = {0, 1, 2} · · ·定义完0之后,用0来定义1,然后用0和1来定义2,再用0、1和2来定义3……以此类推。这种做法与上面例题里的集合S0~S3在生成方法和结构上都是一样的(正是为了便于比较,例子里的位次才从0开始)。这道题很好地直接结合了SQL和集合论,而联系二者的正是自连接。 另外这个子查询的代码还可以像下面这样按照自连接的写法来改写。 --排序:使用自连接 SELECT P1.name, MAX(P1.price) AS price, COUNT(P2.name) +1 AS rank_1 FROM Products P1 LEFT OUTER JOIN Products P2 ON P1.price < P2.price GROUP BY P1.name ORDER BY rank_1;去掉这条SQL语句里的聚合并展开成下面这样,就可以更清楚地看出同心圆状的包含关系(为了看得更清楚,我们从表中去掉价格重复的行,只留下橘子、西瓜、葡萄和柠檬这4行)。 --不聚合,查看集合的包含关系 SELECT P1.name, P2.name FROM Products P1 LEFT OUTER JOIN Products P2 ON P1.price < P2.price;结果:  从执行结果可以看出,集合每增大1个,元素也增多1个,通过数集合里元素的个数就可以算出位次。 此外,这个查询里还有一个特别的技巧,也许大家已经注意到了。那就是前面的例子里用的连接都是标准的内连接,而这里用的却是外连接。如果将外连接改为内连接看一看,马上就会明白这样做的原因。 --排序:改为内连接 SELECT P1.name, MAX(P1.price) AS price, COUNT(P2.name) +1 AS rank_1 FROM Products P1 INNER JOIN Products P2 ON P1.price < P2.price GROUP BY P1.name ORDER BY rank_1;结果: --没有第1名! name price rank_1 ------ ------- -------- 西瓜 80 2 葡萄 50 3 苹果 50 3 香蕉 50 3 柠檬 30 6没错,第1名“橘子”竟然从结果里消失了。关于这一点大家思考一下就能理解了。没有比橘子价格更高的水果,所以它被连接条件P1.price < P2.price排除掉了。外连接就是这样一个用于将第1名也存储在结果里的小技巧(这个小技巧在之后的内容中还会再次提到)。 05、小结这篇文章中,我们通过4个例子学习了自连接的一些知识。自连接是不亚于CASE表达式的重要技术,大家一定要熟练掌握。最后说一个需要注意的地方,与多表之间进行的普通连接相比,自连接的性能开销更大(特别是与非等值连接结合使用的时候),因此用于自连接的列推荐使用主键或者在相关列上建立索引。本文例子里出现的连接大多使用的是主键。 以上就是今天分享的全部内容,整理了一份数据分析资料,评论区领取。  想学习数据分析的朋友关注下我,整理不易,点点赞,拜托了! |
【本文地址】